Wenn wir viele Messwerte haben, würden wir sie gerne durch einen »typischen« Wert ersetzen, der meistens in der Mitte vermutet wird. Aber wo genau ist diese Mitte? Das wird in folgendem Video diskutiert (nicht eingebettet):
Der radioaktive Zerfall eines Atomkerns ist ein völlig zufälliger Prozess. Wir können nicht vorhersagen, wann ein bestimmter Kern zerfallen wird. Daher wissen wir auch nicht genau, wann noch wie viele Kerne nicht zerfallen sind.
kennengelernt. Dabei ist die Zahl der zu Beginn vorhandenen Kerne, die Anzahl der zur Zeit t noch nicht zerfallenen Kerne und ist die Zerfallskonstante des Materials. Das ist ein exakter funktionaler Zusammenhang.
Wie kann ein völlig zufälliger Vorgang zu einem exakten Gesetz führen?
Unlängst haben wir uns gefragt: »Wie weit können Messwerte vom Mittelwert abweichen?« Dieses Mal diskutieren wir den Median und seine Eigenschaften. Wir werden zeigen, dass der Abstand des Medians m zum Mittelwert immer kleiner oder gleich der Standardabweichung ist:
.
(Im Rahmen dieses Beitrags nehmen wir an, dass die Messwerte zumindest intervallskaliert sind.)
Unterwegs werden wir dabei zwei wichtige Ungleichungen besprechen.
Wenn wir eine Größe oft gemessen haben, möchten wir statt allen Messwerten einfach einen typischen Wert angeben. Wie groß ist z.B. das typische Einkommen aller Österreicher? Oft wird dafür das arithmetische Mittel verwendet, das eigentlich der Schwerpunkt der Messwerte ist. (Wie weit Mittelwert und Median voneinander abweichen können, wird hier diskutiert.)
Die einzelnen Messwerte streuen mehr oder weniger weit um diesen Mittelwert. Ein Maß für die Streuung ist die Standardabweichung . Als typischer Bereich der Werte wird oft das Intervall verwendet.
Aber wie viele Werte sind wirklich in diesem Bereich bzw. wie weit können die Messwerte überhaupt vom Mittelwert abweichen? Wie wir sehen werden, ist der Bereich, in dem garantiert mindestens die Hälfte der Messwerte liegt. Und typisch kann ja nur etwas sein, was zumindest für die Hälfte zutrifft. Darüber hinaus liegen sicher alle n Messwerte im Intervall .
Wenn man sich für eine bestimmte Eigenschaft einer (großen) Grundgesamtheit interessiert, könnte man natürlich hergehen, und sie tatsächlich für alle Angehörigen der Grundgesamtheit messen. Man könnte also z.B. bei jeder Schweißnaht prüfen, bei welcher Kraft sie wirklich reißt, oder jede Woche alle Wähler befragen, wen sie denn wählen möchten, oder …
Wie die obigen Beispiele zeigen, kann man das, was man von Allen wissen will, praktisch eben nicht immer an Allen messen.
Vielleicht ist das Messverfahren zerstörend, oder es ist zu teuer, oder man ist einfach zu faul. In solchen Fällen zieht man eine (kleine) Stichprobe aus der Grundgesamtheit und macht die Messungen nur in dieser Probe. Die Preisfrage lautet jetzt natürlich: Was können wir aus unseren Ergebnissen in der Stichprobe über die Grundgesamtheit aussagen?
Angenommen, man hat eine Messgröße, die man durch eine Zufallsvariable modellieren kann. Der Erwartungswert von sei und die Standardabweichung sei .
Misst man diese Messgröße mehrfach, wird man voraussichtlich verschiedene Werte erhalten, deren Streuung durch die Verteilung von modelliert wird.
Berechnet man den Mittelwert dieser Messungen, kann man ihn durch die Zufallsvariable modellieren. Wenn die Messungen alle voneinander unabhängig waren, gilt für den Erwartungswert des Mittelwertes
und für die Standardabweichung (»Standardfehler«) des Mittelwertes
Diese Formeln gelten unabhängig von der konkreten Verteilung von ; die zweite wird oft auch als »Wurzel-n-Gesetz« bezeichnet.
Im letzten Beitrag haben wir gesehen, wie in einem längeren Münzwurfexperiment die relative Häufigkeit für Kopf immer näher an 1/2 herangekommen ist. Obwohl es keine Garantie dafür gibt, dass es so sein muss, ist so eine Stabilisierung von relativen Häufigkeiten und anderen Messgrößen oft zu beobachten. Diese Erfahrungstatsache nennt man das empirische »Gesetz« der großen Zahlen.
Wahrscheinlichkeiten sind Erwartungen – um nicht zu sagen Hoffnungen – darüber, wie oft ein bestimmtes Ereignis bei oftmaliger Wiederholung eines Zufallsexperiments (unter gleichen Bedingungen) eintreten wird. Genauer gesagt, geht es um die relative Häufigkeit eines Ereignisses.
Diese Erwartungen hängen von unserem Informationsstand ab. Wie man zu sinnvollen Erwartungen kommt, ist ein Kapitel für sich. Erwartungen können falsch sein; selbst »richtige« Erwartungen können enttäuscht werden.
Darüber hinaus ist unklar, was mit oftmaliger Wiederholung genau gemeint ist. 100-mal, 1000-mal, 1 Milliarde Mal?
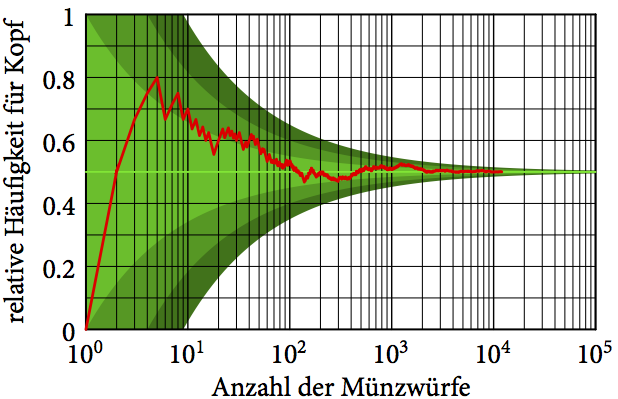
Für viele Münzwurfexperimente ist es sinnvoll, eine Wahrscheinlichkeit für Kopf von 1/2 anzunehmen. Die rote Linie in der folgenden Abbildung zeigt, wie sich die relative Häufigkeit für Kopf im Lauf einer längeren Münzwurfserie geändert hat.
Die laufende relative Häufigkeit für Kopf als Funktion der Anzahl der Münzwürfe (rote Linie). Die grün gefüllten Bereiche stellen die -, – bzw. -Umgebungen unserer Erwartung dar. Die horizontale Achse ist logarithmisch skaliert, um den Beginn deutlicher zeigen zu können.




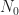 die Zahl der zu Beginn vorhandenen Kerne,
die Zahl der zu Beginn vorhandenen Kerne,  die Anzahl der zur Zeit t noch nicht zerfallenen Kerne und
die Anzahl der zur Zeit t noch nicht zerfallenen Kerne und 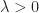 ist die Zerfallskonstante des Materials. Das ist ein exakter funktionaler Zusammenhang.
ist die Zerfallskonstante des Materials. Das ist ein exakter funktionaler Zusammenhang. immer kleiner oder gleich der Standardabweichung
immer kleiner oder gleich der Standardabweichung  ist:
ist: .
.![[\bar{x}-s_n;\bar{x}+s_n]](https://s0.wp.com/latex.php?latex=%5B%5Cbar%7Bx%7D-s_n%3B%5Cbar%7Bx%7D%2Bs_n%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) verwendet.
verwendet.![[\bar{x}-\sqrt{2}\,s_n;\bar{x}+\sqrt{2}\,s_n]](https://s0.wp.com/latex.php?latex=%5B%5Cbar%7Bx%7D-%5Csqrt%7B2%7D%5C%2Cs_n%3B%5Cbar%7Bx%7D%2B%5Csqrt%7B2%7D%5C%2Cs_n%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) der Bereich, in dem garantiert mindestens die Hälfte der Messwerte liegt. Und typisch kann ja nur etwas sein, was zumindest für die Hälfte zutrifft. Darüber hinaus liegen sicher alle n Messwerte im Intervall
der Bereich, in dem garantiert mindestens die Hälfte der Messwerte liegt. Und typisch kann ja nur etwas sein, was zumindest für die Hälfte zutrifft. Darüber hinaus liegen sicher alle n Messwerte im Intervall ![[\bar{x}-\sqrt{n-1}\cdot s_n;\bar{x}+\sqrt{n-1}\cdot s_n]](https://s0.wp.com/latex.php?latex=%5B%5Cbar%7Bx%7D-%5Csqrt%7Bn-1%7D%5Ccdot+s_n%3B%5Cbar%7Bx%7D%2B%5Csqrt%7Bn-1%7D%5Ccdot+s_n%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. einer (großen) Grundgesamtheit interessiert, könnte man natürlich hergehen, und sie tatsächlich für alle Angehörigen der Grundgesamtheit messen. Man könnte also z.B. bei jeder Schweißnaht prüfen, bei welcher Kraft sie wirklich reißt, oder jede Woche alle Wähler befragen, wen sie denn wählen möchten, oder …
einer (großen) Grundgesamtheit interessiert, könnte man natürlich hergehen, und sie tatsächlich für alle Angehörigen der Grundgesamtheit messen. Man könnte also z.B. bei jeder Schweißnaht prüfen, bei welcher Kraft sie wirklich reißt, oder jede Woche alle Wähler befragen, wen sie denn wählen möchten, oder … und die Standardabweichung sei
und die Standardabweichung sei 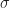 .
. Messungen, kann man ihn durch die Zufallsvariable
Messungen, kann man ihn durch die Zufallsvariable 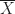 modellieren. Wenn die Messungen alle voneinander unabhängig waren, gilt für den Erwartungswert des Mittelwertes
modellieren. Wenn die Messungen alle voneinander unabhängig waren, gilt für den Erwartungswert des Mittelwertes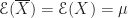

 -,
-,  – bzw.
– bzw. 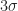 -Umgebungen unserer Erwartung dar. Die horizontale Achse ist logarithmisch skaliert, um den Beginn deutlicher zeigen zu können.
-Umgebungen unserer Erwartung dar. Die horizontale Achse ist logarithmisch skaliert, um den Beginn deutlicher zeigen zu können.