
Im letzten Teil haben wir die Objekte in unserer Szene bewegt, indem wir sie mit Transformationsmatrizen aus einer Standardlage heraus verdreht, skaliert und verschoben haben. In diesem Teil werden wir jetzt die Kamera »bewegen« – bzw. den Rest der Welt genau umgekehrt.
Wir wollen uns mit der Kamera durch eine Szene bewegen können, z.B. in einem Flugsimulator. Ein einfaches Beispiel einer bewegten Kamera ist in Abb. 1 gezeigt. Unsere Kamera soll eine Szene umkreisen und immer in deren Mitte schauen. Die Kamera ist dabei etwas unterhalb und zeigt leicht nach oben.
Unsere Kamera ist die weiße Pyramide in der Animation. Ihre Spitze ist das Loch der inversen Lochkamera (eye point bzw. Augpunkt) und die quadratische Grundfläche ist der Schirm. Und ja, unsere Standardkamera ist so groß im Vergleich zu den Objekten und auch so nah dran. Wie wir das ändern können, sehen wir im nächsten Beitrag.
Ausrichtung und Verschiebung
Wie können wir unsere Kamera ausrichten und verschieben? Abb. 2 zeigt noch einmal die Standardkamera. Sie schaut gegen die z-Richtung und der Schirm befindet sich bei 

 ,
,  und
und  zeigen in die x-, y– bzw. z-Richtung.
zeigen in die x-, y– bzw. z-Richtung.Aus Sicht der Kamera geht es in x-Richtung nach rechts und in y-Richtung nach oben. Der Pfeil auf dem Schirm zeigt aus Kamerasicht also nach rechts oben. Diese Ausrichtung können wir durch die Einheitsvektoren 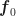
Für die Standardkamera sind die Vektoren
Wenn wir unsere Kamera zum Ausrichten verdrehen, drehen sich diese Einheitsvektoren mit (s. Abb. 3). Dabei bleiben aber ihre Längen und die Winkel zwischen ihnen gleich. Sie bilden also immer noch ein rechtshändiges, orthonormales Dreibein.
 , und mit.
, und mit.Um die Kamera zu transformieren, müssen wir nur wissen, was aus den Einheitsvektoren in x-, y– und z-Richtung wird. Wie wir in Teil 2 gesehen haben, sind die Bilder dieser Einheitsvektoren die Spalten der Transformationsmatrix.
Der Einheitsvektor in x-Richtung (die alte Richtung rechts) soll auf den Vektor
Diese Ausrichtung der Kamera schaffen wir daher mit der Rotationsmatrix
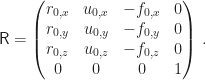
Anschließend müssen wir die Kamera noch mit der Translationsmatrix 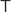

Insgesamt haben wir dann die Kamera-Transformation (camera transformation)
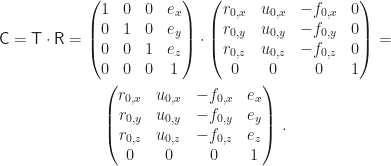
Die Kamera-Matrix (camera matrix) 
Mit dieser Kamera-Matrix können wir die Kamera in der Welt ausrichten und verschieben. Allerdings müssten wir dann unsere einfache Projektion aus Teil RS1 je nach Augpunkt und Ausrichtung anpassen. Das ist etwas mühsam.
In dieser Hinsicht wäre es einfacher, wir würden den Rest der Welt genau umgekehrt ausrichten und verschieben. Dann muss unsere Kamera nicht bewegt werden und die Projektion erfolgt immer gleich.
In der Realität ist das unmöglich, aber im Computer können wir rechnen, was wir wollen. Wir müssen auf den Rest unserer Welt nur die Inverse
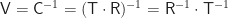
der Kamera-Matrix anwenden.
Die View Transformation
Die Verschiebung in den Augpunkt rückgängig machen ist relativ einfach:
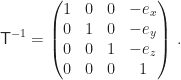
Aber wie bekommen wir die Inverse des interessanten Teils von 

(Warum das der interessante Teil ist, steht im Anhang.)
Wenn wir die Inverse direkt berechnen, ist das aufwändig. Aber wir können uns das Folgende überlegen: Unsere Einheitsvektoren in x-, y– und z-Richtung haben alle die Länge 1 und stehen senkrecht aufeinander, und das gilt auch für unsere neues Dreibein
Abbildungen mit dieser Eigenschaft nennt man orthogonal, und sie werden durch orthogonale Matrizen dargestellt. Eine nette Eigenschaft solcher Matrizen ist, dass ihre Inverse einfach die transponierte Matrix ist. Wir müssen daher nur Zeilen und Spalten vertauschen:

Voraussetzung ist natürlich, dass wir unsere Vektoren
Insgesamt bekommen wir als view matrix (bzw. lookAt matrix)
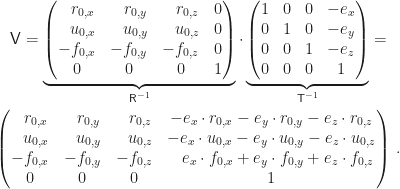
Wenn wir genau hinschauen, erkennen wir in der letzten Spalte die Skalarprodukte von 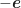
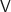

schreiben.
Diese komische Skalarprodukte kann man auch so erklären: Aus Sicht der Kamera müssen wir den Rest der Welt ein Stück in Vorwärtsrichtung verschieben. Und dieses Stück ist die Projektion von
Die view matrix wenden wir zusätzlich an, nachdem wir unsere Objekte mit der model transformation in der Welt platziert haben. Für jedes Objekt multiplizieren wir einfach die view matrix mit der model matrix und erhalten die sogenannte model view matrix. Mit dieser werden dann alle Punkte des Objekts transformiert.
Das Resultat zeigt die Animation in Abb. 4. Unsere Kamera steht fix, der Rest der Welt ist gekippt und dreht sich um eine Achse. Die Kippung kommt daher, dass wir von leicht unten schauen wollen. Außerdem wollen wir die Kamera rechts herum drehen, also muss der Rest der Welt sich links herum drehen.
Aus Sicht der Standardkamera schaut es dann so aus wie in Abb. 5. Scheinbar schauen wir von leicht unten auf die Objekte und bewegen uns um sie herum. Genau das, was wir erreichen wollten.
Eye und LookAt
Wie kommen wir jetzt sinnvoll zu unserem Kameradreibein
Wir brauchen auf jeden Fall die Position der Kamera, also den Ortsvektor des eye points 

festgelegt.
Um die Achse des Vorwärtsvektors könnten wir unsere Kamera jetzt noch verdrehen. Um die Orientierung festzulegen, reicht uns ein Vektor 
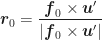
nach rechts ausrechnen.
Die Orientierung des Kreuzprodukts erhalten wir mit der »Rechten-Hand-Regel«. Der Daumen der rechten Hand zeigt nach vorne (
Wir müssen dabei nur aufpassen, das der Vektor
Jetzt haben wir zwei normierte Vektoren, die senkrecht aufeinander stehen. Ohne weitere Normierung bekommen wir mittels Kreuzprodukt noch

den Vektor exakt nach oben: Daumen der rechten Hand nach rechts (
Code
In unserem Programm kommt jetzt eine neue Klasse für die Kamera dazu.
class Camera {
// speichert die view matrix
Transform3D viewTransform;
// der Konstruktor legt die Einheitsmatrix als
// view transformation fest
Camera() {
viewTransform = new Transform3D();
}
// setzt die view matrix der Kamera
// auf die Einheitsmatrix zurück
void resetTrafo() {
viewTransform = new Transform3D();
}
// berechnet die view matrix aus Augpunkt eye,
// Zielpunkt lookAt und dem Vektor up, der in etwa
// nach oben zeigt
void setEyeAndLookAt(final Point3D eye, final Point3D lookAt, final Vec3D up) {
Vec3D fwd0 = Vec3D_normalize(lookAt.minus(eye));
Vec3D right0 = Vec3D_normalize(fwd0.cross(up));
Vec3D up0 = right0.cross(fwd0);
viewTransform = new Transform3D(right0.x, right0.y, right0.z, -eye.dot(right0),
up0.x, up0.y, up0.z, -eye.dot(up0),
-fwd0.x, -fwd0.y, -fwd0.z, eye.dot(fwd0),
0.0, 0.0, 0.0, 1.0);
}
}
Die Methode setEyeAndLookAt(final Point3D eye, final Point3D lookAt, final Vec3D up) berechnet unsere view transformation – genau wie oben gezeigt.
Dazu benötigen wir das Kreuzprodukt, das in einer eigenen Vektor-Klasse definiert ist.
class Vec3D {
// die Komponenten des Vektors
final float x;
final float y;
final float z;
// der Konstruktor speichert die Komponenten einfach ab
Vec3D(final float x, final float y, final float z) {
this.x = x;
this.y = y;
this.z = z;
}
// berechnet das Kreuzprodukt dieses Vektors mit dem Vektor v
Vec3D cross(final Vec3D v) {
return new Vec3D(y*v.z - z*v.y,
z*v.x - x*v.z,
x*v.y - y*v.x);
}
}
// berechnet die Länge des Vektors v
float Vec3D_norm(Vec3D v) {
return sqrt(v.x*v.x + v.y*v.y + v.z*v.z);
}
// berechnet den Einheitsvektor v_0 zum Vektor v
Vec3D Vec3D_normalize(Vec3D v) {
float m = 1.0/Vec3D_norm(v);
return new Vec3D(m*v.x, m*v.y, m*v.z);
}
Außerdem kann die Punkt-Klasse jetzt den Differenzvektor zwischen zwei Punkten berechnen und den Ortsvektor zum Punkt skalar mit einem Vektor multiplizieren.
class Point3D {
// die Koordinaten des Punktes
final float x;
final float y;
final float z;
// weil die w-Koordinate der Punkte vorerst immer 1 ist,
// speichern wir sie gar nicht erst ab
// final float w = 1.0;
// der Konstruktor speichert die Koordinaten einfach ab
Point3D(final float x, final float y, final float z) {
this.x = x;
this.y = y;
this.z = z;
}
// berechnet den Differenzvektor vom Punkt p
// zu diesem Punkt ("Spitze-minus-Schaft")
Vec3D minus(final Point3D p) {
return new Vec3D(x - p.x, y - p.y, z - p.z);
}
// berechnet das Skalarprodukt des Ortsvektors zum Punkt
// mit dem Vektor v
float dot(final Vec3D v) {
return x * v.x + y * v.y + z * v.z;
}
}
// berechnet den Abstand eines Punkts zum Ursprung
float Point3D_norm(Point3D p) {
return sqrt(p.x*p.x + p.y*p.y + p.z*p.z);
}
Dem Rasterizer müssen wir jetzt auch die Kamera bekannt machen. Bisher haben wir in der Methode stageLines() nur die model transformation angewandt.
// jetzt wird die Model-Transformation auf alle Punkte
// angewandt und das Ergebnis eingefügt
for (Point3D v : wf.vertices) {
Point3D p = wf.applyModelTransform(v);
vertices.add(p);
// falls die z-Koordinate größer als die bisher maximale
// ist, speichern wir sie
maxZ = max(maxZ, p.z);
}
Jetzt müssen wir zuerst die view matrix mit der model matrix multiplizieren.
// die View-Transformation der Kamera und die Model-Transformation des
// aktuellen Objekts werden zur Model-View-Transformation multipliziert
Transform3D t = Transform3D_mulAB(camera.viewTransform, wf.modelTransform);
// jetzt wird die Model-View-Transformation auf alle Punkte
// angewandt und das Ergebnis eingefügt
for (Point3D v : wf.vertices) {
Point3D p = t.apply(v);
vertices.add(p);
// falls die z-Koordinate größer als die bisher maximale
// ist, speichern wir sie
maxZ = max(maxZ, p.z);
}
Der Rest kann gleich bleiben, weil wir ja die Standardkamera nie wirklich verändert haben.
In der draw()-Methode müssen wir jetzt zu Beginn die Position der Kamera definieren. Wir drehen uns dabei mit Radius 2 um den Punkt 
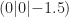
void draw() {
// wir füllen das Fenster schwarz
background(0);
int t = millis(); // Zeit seit Beginn der Animation in ms
alpha = omega*t*1.0e-3; // *1.0e-3 Umrechnung ms -> s
float r = 2.0;
float eye_y = -1.0;
// Kamera ausrichten und positionieren
theCamera.setEyeAndLookAt(new Point3D(r*sin(alpha), eye_y, -1.5 + r*cos(alpha)),
new Point3D(0.0, 0.0, -1.5),
new Vec3D(0.0, 1.0, 0.0));
// die Objekte werden in jedem Frame neu transformiert
c1.resetTrafo();
c1.scale(0.25, 0.375, 0.5);
c1.translate(0.0, -0.75, -1.5);
c2.resetTrafo();
c2.scale(0.25);
c2.translate(-0.75, 0.75, -1.5);
c3.resetTrafo();
c3.scale(0.25);
c3.translate(0.75, 0.75, -1.5);
s1.resetTrafo();
s1.scale(0.35);
s1.translate(0.0, 0.35, -1.5);
// der Rasterizer erhält zuerst die zu malenden
// Linien der Szene und malt sie dann
theRasterizer.stageLines();
theRasterizer.paintScene();
}
Der gesamte Processing-Code kann hier heruntergeladen werden. Die Codes für die Animationen mit einer zweiten Kamera aus Abb. 1 und Abb. 4 finden sich hier bzw. hier.
Diskussion
Wir haben gesehen, dass die »Bewegung der Kamera« einfach eine weitere Multiplikation mit einer Matrix ist. Das macht die Sache natürlich sehr elegant. Andererseits zeigt es auch, dass wir ohne Matrizen nicht mehr sehr weit kommen. Zusätzlich haben wir jetzt aus der Vektorrechnung noch Skalar- und Kreuzprodukt benötigt.
Im nächsten Teil werden wir mit der Kamera dann noch zoomen und die Sensorgröße ändern. Auch das erledigt eine weitere Matrizenmultiplikation.
Anhang
Warum ist

der interessante Teil von

Nennen wir die inverse Matrix 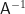





Die letzte Zeile von 
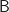
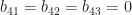

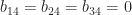

führt.
Bleibt also nur noch
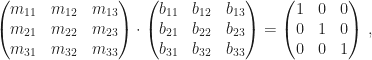
und daher muss

sein.
