
Wenn man sich für eine bestimmte Eigenschaft 
Wie die obigen Beispiele zeigen, kann man das, was man von Allen wissen will, praktisch eben nicht immer an Allen messen.
Vielleicht ist das Messverfahren zerstörend, oder es ist zu teuer, oder man ist einfach zu faul. In solchen Fällen zieht man eine (kleine) Stichprobe aus der Grundgesamtheit und macht die Messungen nur in dieser Probe. Die Preisfrage lautet jetzt natürlich: Was können wir aus unseren Ergebnissen in der Stichprobe über die Grundgesamtheit aussagen?
Die Stichprobe
Wie wählen wir die Mitglieder der Stichprobe aus? Testen wir nur alle Schweißnähte, die uns verdächtig erscheinen, oder nur die vom Kollegen S., dem Pfuscher? Befragen wir einfach die ersten 100 Leute im Telefonbuch?
Die wichtigste Voraussetzung für alles Weitere ist, dass unsere Stichprobe für die Grundgesamtheit repräsentativ ist. D.h., dass alle Elemente der Grundgesamtheit die gleiche Wahrscheinlichkeit haben sollen, in die Stichprobe zu kommen. Leider ist das ist in der Praxis nicht immer sicherzustellen. Auf jeden Fall sollten wir Auswahlmethoden vermeiden, die garantiert zu keinen repräsentativen Stichproben führen.
Die Messgröße
Die Details im Folgenden hängen von der Art der Größe ab, die man bestimmen möchte. Wenn man die Größe 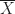
Wenn wir z.B. von zehn Flaschen die Füllmenge bestimmt haben, was können wir dann über die mittlere Füllmenge aller Flaschen (derselben Produktion) sagen?
Das Modell
Um überhaupt sinnvolle Rückschlüsse von der Stichprobe auf die Grundgesamtheit durchführen zu können, müssen wir eine Ahnung haben, wie die möglichen Werte unserer Messgröße
Anschließend modellieren wir unsere Messgröße 
Falls wir annehmen können, dass unsere Messgröße näherungsweise normalverteilt ist, können wir jede Messung in der Stichprobe durch eine Ziehung aus der Zufallsvariablen
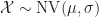
modellieren. In diesem Fall wird der Mittelwert
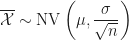
modelliert, wobei 
Falls wir die Verteilung von
In jedem Fall gelten für den Erwartungswert 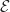


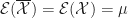

Die Punktschätzung
Wie nicht weiter überraschend, schätzen wir den Erwartungswert 

Weil man nur einen Wert als Schätzung hat, spricht man von einer Punktschätzung.
Bsp.: Wir haben von 

In der Statistiksoftware R hätten wir das z.B. so berechnen können:
x <- c(500.1, 500.5, 501.5, 502.7, 499.6, 501.2, 498.2, 501.9, 503.8, 497.8) mean(x)
Wo dieser Schätzwert relativ zu unserem unbekannten 
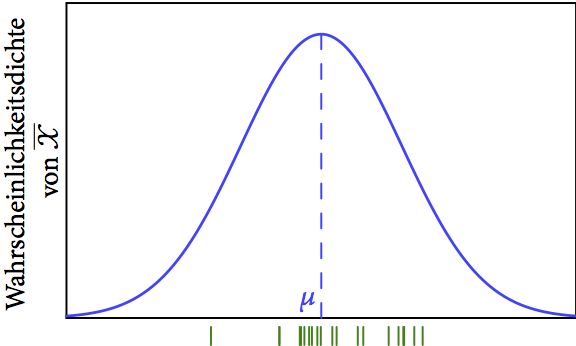 als andere, wir wissen aber nicht welche.
als andere, wir wissen aber nicht welche.Um mehr über unser gesuchtes
Das z-Konfidenzintervall
Wir setzen fürs Erste voraus, dass wir die Standardabweichung 
Der gemessene Mittelwert einer zufälligen Stichprobe ist ebenfalls zufällig. Wie wir oben gesehen haben, kann er viele beliebige Werte annehmen, aber wahrscheinlich wird er in der »Nähe« des gesuchten 



gelten. Leider können wir das Intervall
![\displaystyle\left[\mu - \frac{b}{2}; \mu + \frac{b}{2}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cleft%5B%5Cmu+-+%5Cfrac%7Bb%7D%7B2%7D%3B+%5Cmu+%2B+%5Cfrac%7Bb%7D%7B2%7D%5Cright%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
nicht berechnen, weil wir – wie schon erwähnt –
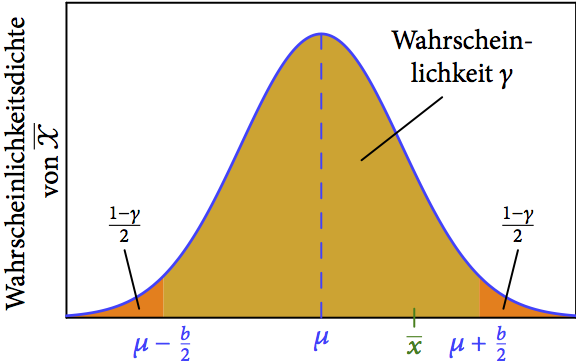 einer Stichprobe liegt mit Wahrscheinlichkeit in dem braun schraffierten Bereich symmetrisch um das unbekannte . Die beiden orangenen Zwickel repräsentieren jeweils eine Wahrscheinlichkeit von
einer Stichprobe liegt mit Wahrscheinlichkeit in dem braun schraffierten Bereich symmetrisch um das unbekannte . Die beiden orangenen Zwickel repräsentieren jeweils eine Wahrscheinlichkeit von  .
.Was wir aber kennen ist unser gemessenes
![\displaystyle\left[\overline{x} - \frac{b}{2}; \overline{x} + \frac{b}{2}\right] = \left[\mu_\text{unten}; \mu_\text{oben}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cleft%5B%5Coverline%7Bx%7D+-+%5Cfrac%7Bb%7D%7B2%7D%3B+%5Coverline%7Bx%7D+%2B+%5Cfrac%7Bb%7D%7B2%7D%5Cright%5D+%3D+%5Cleft%5B%5Cmu_%5Ctext%7Bunten%7D%3B+%5Cmu_%5Ctext%7Boben%7D%5Cright%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
mit derselben Wahrscheinlichkeit den unbekannten Wert
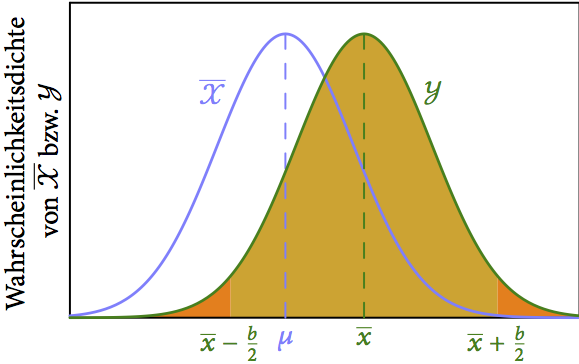
![\left[\overline{x} - \frac{b}{2}; \overline{x} + \frac{b}{2}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Coverline%7Bx%7D+-+%5Cfrac%7Bb%7D%7B2%7D%3B+%5Coverline%7Bx%7D+%2B+%5Cfrac%7Bb%7D%7B2%7D%5Cright%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) überdeckt den unbekannten Wert mit Wahrscheinlichkeit .
überdeckt den unbekannten Wert mit Wahrscheinlichkeit .Wir können also statt der Zufallsvariable 
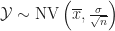

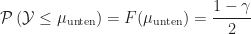
bzw.

Durch Umkehrung der kummulativen Verteilungsfunktion 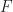

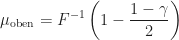
Die Umkehrfunktion 
qnorm. In unserem Beispiel hätten wir das Konfidenzintervall also folgendermaßen berechnen können:
n <- 10 x_quer <- 500.73 sigma <- 2.0 gamma <- 0.95 mu_unten <- qnorm((1.0 - gamma) / 2.0, x_quer, sigma / sqrt(n)) mu_oben <- qnorm(1.0 - (1.0 - gamma) / 2.0, x_quer, sigma / sqrt(n))
Damit erhalten wir das 
![[499.5, 502.0]](https://s0.wp.com/latex.php?latex=%5B499.5%2C+502.0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
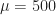
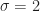
Obige Berechnung verdeckt ein bisschen, wovon die Breite des Konfidenzintervalls abhängt. Wir werden die Berechnung jetzt also etwas expliziter machen. Zunächst standardisieren wir die Zufallsvariable

und erhalten die ebenfalls normalverteilte Zufallsvariable 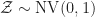
Wie Abb. 4 zeigt, ist unser standardisiertes Intervall ![[-z,+z]](https://s0.wp.com/latex.php?latex=%5B-z%2C%2Bz%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)




mittels der inversen kummulativen Verteilungsfunktion 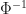

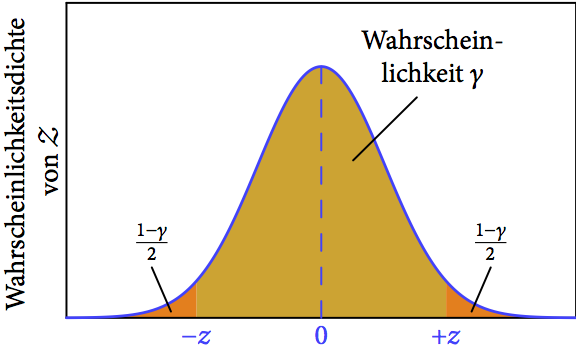 -Streubereich einer standard-normalverteilten Zufallsvariable
-Streubereich einer standard-normalverteilten Zufallsvariable  . Die beiden orangenen Flachen haben jeweils den Flächeninhalt .
. Die beiden orangenen Flachen haben jeweils den Flächeninhalt .Im zweiten Schritt kehren wir die Standardisierung mittels
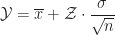
um, und erhalten das
![\displaystyle\left[\overline{x} - z \cdot \frac{\sigma}{\sqrt{n}},\overline{x} + z \cdot \frac{\sigma}{\sqrt{n}}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cleft%5B%5Coverline%7Bx%7D+-+z+%5Ccdot+%5Cfrac%7B%5Csigma%7D%7B%5Csqrt%7Bn%7D%7D%2C%5Coverline%7Bx%7D+%2B+z+%5Ccdot+%5Cfrac%7B%5Csigma%7D%7B%5Csqrt%7Bn%7D%7D%5Cright%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Die Breite des Intervalls ist also

Wenn wir unsere Konfidenz 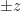


Weiters hängt die Breite von dem Faktor 
Um bei unserem Beispiel zu bleiben:
n <- 10 x_quer <- 500.73 sigma <- 2.0 gamma <- 0.95 z <- -qnorm((1.0 - gamma) / 2.0) mu_unten <- x_quer - z * sigma / sqrt(n) mu_oben <- x_quer + z * sigma / sqrt(n)
Dabei ist 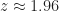
Wenn wir statt dem Mittelwert die einzelnen Werte gegeben haben, könnten wir
x <- c(500.1, 500.5, 501.5, 502.7, 499.6, 501.2, 498.2, 501.9, 503.8, 497.8) n <- length(x) x_quer <- mean(x) sigma <- 2.0 …
verwenden.
Das t-Konfidenzintervall
Wenn wir – was der übliche Fall ist – die Standardabweichung
Eine Idee ist es, die Standardabweichung

der Stichprobe zu schätzen. Für unser Beispiel erhalten wir 
sd:
x <- c(500.1, 500.5, 501.5, 502.7, 499.6, 501.2, 498.2, 501.9, 503.8, 497.8) s <- sd(x)
Wir könnten also statt 

Für kleine Stichproben kann man zeigen, dass die »Standardisierung«

zu einer Zufallsvariablen 
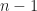

Abb. 5 vergleicht zwei t-Verteilungen mit 1 bzw. 5 Freiheitsgraden mit einer Standardnormalverteilung. Man sieht, dass mit der Größe der Stichprobe die t-Verteilung der Normalverteilung immer ähnlicher wird; der zentrale Grenzwertsatz gilt ja weiterhin. Für kleinere
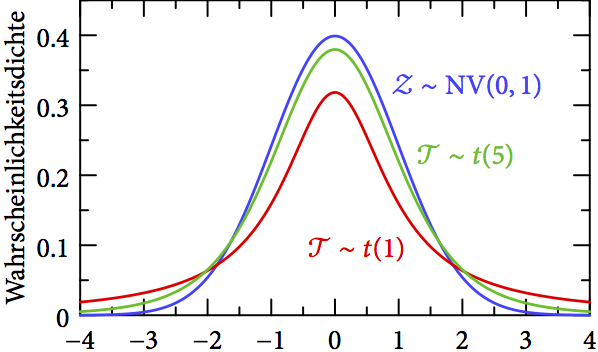
 Freiheitsgraden (Mittelwert aus 2 Messungen; rot), einer t-Verteilung mit
Freiheitsgraden (Mittelwert aus 2 Messungen; rot), einer t-Verteilung mit  Freiheitsgraden (Mittelwert aus 6 Messungen; grün) und einer Standardnormalverteilung (blau).
Freiheitsgraden (Mittelwert aus 6 Messungen; grün) und einer Standardnormalverteilung (blau).Abgesehen von der Verwendung der t-Verteilung (t <- -qt((1.0 - gamma) / 2.0, n - 1)) statt der Standardnormalverteilung (z <- -qnorm((1.0 - gamma) / 2.0)), verläuft die Berechnung identisch zu der obigen detaillierten Variante. Für unser Beispiel erhalten wir mit
x <- c(500.1, 500.5, 501.5, 502.7, 499.6, 501.2, 498.2, 501.9, 503.8, 497.8) n <- length(x) x_quer <- mean(x) s <- sd(x) gamma <- 0.95 t <- -qt((1.0 - gamma) / 2.0, n - 1) mu_unten <- x_quer - t * s / sqrt(n) mu_oben <- x_quer + t * s / sqrt(n)
als ![[499.4; 502.1]](https://s0.wp.com/latex.php?latex=%5B499.4%3B+502.1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
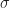



Um noch einmal auf die Frage zurückzukommen, was denn eine kleine Stichprobe ist: Die folgende Tabelle zeigt, um welchen Faktor das 
Üblicherweise hört man, dass Stichproben unter 

Messgenauigkeit
Bisher haben wir angenommen, dass alle Zahlen exakt wären; es also keine Messunsicherheit gibt. Wenn wir Füllmengen auf sub-mL genau messen können, bekommen wir ein bestimmtes Konfidenzintervall. Wenn wir die Flascheninhalte in ein Gefäß mit einer 1L-Marke schütten, können wir bestenfalls sagen, dass jede Flasche etwa 0.5L Inhalt hatte, und bekommen wieder dasselbe Konfidenzintervall. Das ist offensichtlich absurd! Je ungenauer wir messen, desto breiter müsste unser Konfidenzintervall werden.
Wenn wir auf 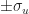


modellieren.
In unserem Beispiel beschreibt 

weil die Summe zweier unabhängiger, normalverteilter Zufallsvariable wieder normalverteilt ist, allerdings mit einer größeren Breite (die unserer größeren Unsicherheit entspricht).
Für den Mittelwert aus

Analog zu oben erhalten wir dann das
![\displaystyle\left[\overline{x} - z \cdot \frac{\sqrt{\sigma^2 + \sigma_u^2}}{\sqrt{n}},\overline{x} + z \cdot \frac{\sqrt{\sigma^2 + \sigma_u^2}}{\sqrt{n}}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cleft%5B%5Coverline%7Bx%7D+-+z+%5Ccdot+%5Cfrac%7B%5Csqrt%7B%5Csigma%5E2+%2B+%5Csigma_u%5E2%7D%7D%7B%5Csqrt%7Bn%7D%7D%2C%5Coverline%7Bx%7D+%2B+z+%5Ccdot+%5Cfrac%7B%5Csqrt%7B%5Csigma%5E2+%2B+%5Csigma_u%5E2%7D%7D%7B%5Csqrt%7Bn%7D%7D%5Cright%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Der R-Code für unser Beispiel wird daher:
x <- c(500.1, 500.5, 501.5, 502.7, 499.6, 501.2, 498.2, 501.9, 503.8, 497.8) n <- length(x) x_quer <- mean(x) sigma <- 2.0 sigma_u <- 0.05 sigma_ges <- sqrt(sigma^2 + sigma_u^2) gamma <- 0.95 z <- -qnorm((1.0 - gamma) / 2.0) mu_unten <- x_quer - z * sigma_ges / sqrt(n) mu_oben <- x_quer + z * sigma_ges / sqrt(n)
Die folgende Tabelle zeigt, wie sich die
![\begin{array}{cc} \sigma_u & 95\,\%\text{ Konfidenzintervall} \\ \hline 0 & [499.49; 501.97] \\ 0.05 & [499.49; 501.97] \\ 0.5 & [499.45; 502.01] \\ 1 & [499.34; 502.12] \\ 5 & [497.39; 504.07] \\ 10 & [494.41; 507.05] \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bcc%7D+%5Csigma_u+%26+95%5C%2C%5C%25%5Ctext%7B+Konfidenzintervall%7D+%5C%5C+%5Chline+0+%26+%5B499.49%3B+501.97%5D+%5C%5C+0.05+%26+%5B499.49%3B+501.97%5D+%5C%5C+0.5+%26+%5B499.45%3B+502.01%5D+%5C%5C+1+%26+%5B499.34%3B+502.12%5D+%5C%5C+5+%26+%5B497.39%3B+504.07%5D+%5C%5C+10+%26+%5B494.41%3B+507.05%5D+%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Wenn die Messunsicherheit
Diskussion
Nach der Berechnung des Konfidenzintervalls kennen wir den Mittelwert unserer Messgröße
Nachdem wir oben doch einige Annahmen treffen mussten, die in der Praxis nicht wirklich überprüft werden können, ist die Konfidenzwahrscheinlichkeit
