
Im letzten Beitrag haben wir begonnen, unsere Kamera zu »bewegen«. Allerdings war sie immer noch relativ groß und sehr nahe an den Objekten dran. In diesem Beitrag werden wir jetzt die Sensorgröße ändern und zoomen – bzw. mit dem Rest der Welt wieder das Gegenteil machen.
Die Animation in Abb. 1 zeigt unser Ziel: Wir simulieren eine Kleinbildkamera mit einem Bildsensor der Größe 36 mm x 24 mm (»full-frame«). Typischerweise kann man dann verschiedene Objektive aufsetzen, die sich in erster Linie durch ihre Brennweiten unterscheiden. Je größer die Brennweite, desto größer der Zoom.
Die Kamera steht an einem fixen Ort und hat zunächst nahe herangezoomt (Brennweite 135 mm). Anschließend zoomt sie heraus (bis Brennweite 24 mm) und dann wieder hinein. Je kleiner die Brennweite, desto kleiner erscheinen die Objekte. Gleichzeitig sieht man mehr von der Umgebung.
In Abb. 1 befindet sich unsere Kamera 3 m vor einer orangene Kugel mit Durchmesser 0.2 m (ungefähr ein Kopf), 1 m über der blauen Ebene. Die Quadrate in der blauen Ebene haben 1 m Seitenlänge. Die roten Würfel sind in einem Kreis mit Radius 5 m um die orangene Kugel angeordnet. Die grünen Kugeln sind jeweils auf einer Linie 2 m nach hinten angeordnet.
Obwohl sich das Bild dauernd ändert, bewegt sich in dieser Szene nichts – bzw. fast nichts. Abb. 2 zeigt die Situation aus Sicht einer zweiten Kamera.
Unsere Kamera, die Abb. 1 aufnimmt, ist die weiße Pyramide links in der Mitte. Sie ist verglichen mit dem Rest der Welt jetzt relativ klein und weit weg von den anderen Objekten. Ihr Schirm (der Kamerasensor bzw. die near plane) ist auch nicht mehr quadratisch.
Ihre Spitze – der Augpunkt bzw. eye point – bleibt immer an derselben Stelle. Je nach Brennweite bewegt sich aber der Schirm vor und zurück, wodurch sich die Bildweite unserer Lochkamera ändert. Wie wir in Abb. 6 in Teil 1 gesehen haben, ist für Gegenstände, die sich mehr als die 10-fache Brennweite vor der Kamera befinden, die Bildweite ungefähr gleich der Brennweite. Nachdem wir immer 3 m vom Kugelmittelpunkt weg sind, und die maximale Brennweite 0.135 m beträgt, ist diese Bedingung in Abb. 1 jedenfalls erfüllt.
Projektionsmatrix
Wie bekommen wir diese Kamera jetzt in den Computer? Wenig überraschend lautet die Antwort wieder: mit einer Matrix, der sogenannten Projektionsmatrix (projection matrix). Genau genommen werden wir uns nur einen Teil davon anschauen, weil man in die Projektionsmatrix noch andere Dinge hineinstopft (von denen auch ihr Name kommt).
Abb. 3 zeigt noch einmal unsere Standardkamera. Ihr Sensor (die near plane) ist quadratisch mit der Breite 


Beschreiben können wir das wieder mit drei Vektoren der Länge 1: einer nach rechts (


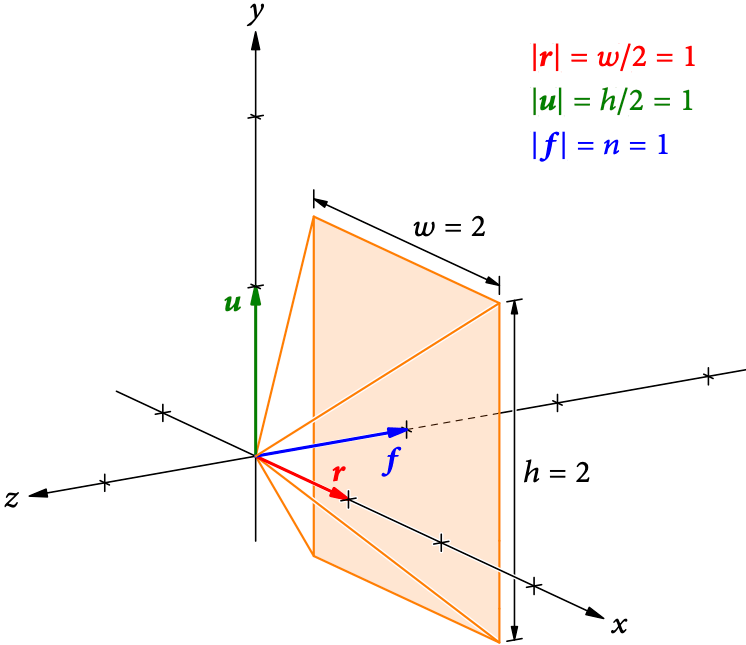
In Abb. 4 ist unsere near plane (der Kamerasensor) jetzt rechteckig mit Breite w und Höhe h, die beide ungleich 2 sind. Außerdem ist die Bildweite n jetzt nicht mehr gleich 1.

Trotzdem können wir die Größe und Lage immer noch mit unseren drei Vektoren
Für die Standardkamera (Abb. 3) sind die Vektoren 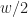

Wenn wir daher auf unsere Standardkamera die Skalierungsmatrix

anwenden, erhalten wir eine Kamera nach unseren Wünschen. Mit der camera transformation 
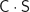
die in Abb. 2 die Kamerapyramide zeichnet.
Wenn wir wie in Abb. 1 umgekehrt auf den Rest der Welt wieder die Inverse obiger Matrix anwenden, also
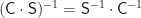
müssen wir unsere Standardkamera effektiv gar nicht ändern.
Um eine Skalierungsmatrix rückgängig zu machen, reicht es, in allen Richtungen mit den Kehrwerten der Skalierungsfaktoren zu multiplizieren. Daher liefert die Inverse 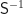

Die Inverse zur camera matrix war die view matrix 

mit der der Rest unseres Universums im Computer transformiert werden muss.
Davor muss jedes Modell noch mit seiner Transformationsmatrix 

anwenden. Dabei ist der
Die Animation in Abb. 5 zeigt, wie das für unsere Szene aussieht. Die weiße Pyramide links ist unsere Standardkamera, deren Spitze (der Augpunkt) im Ursprung des Universums ruht. Der Sensor ist wieder quadratisch mit Seitenlänge 2 und die Bildweite beträgt immer 1.
Unsere zweite Kamera ist bei 

Während in z-Richtung mit 1/n skaliert wird, ist in y-Richtung der Skalierungsfaktor 2/h. Weil unsere Kamera einen relativ kleinen Sensor hat, ist der Rest der Welt realtiv groß verglichen mit der Standardkamera, und in z-Richtung platt gedrückt.
Stellen wir unsere zweite Kamera wie in Abb. 6 hinter die Standardkamera, sehen wir, dass die Standardkamera immer noch einen quadratischen Schirm (Sensor/near plane) hat.
Der Rest der Welt erscheint in x-Richtung aber gestaucht, nachdem mit dem Faktor 2/w skaliert wurde. Diese Stauchung wird wieder rückgängig gemacht, wenn wir bei der Umrechnung von camera coordinates in screen coordinates in beiden Richtungen unterschiedlich skalieren. Bisher hatten wir (s. Teil RS1)
![\displaystyle\begin{aligned}x_S&=\left\lfloor\left(1-\frac{x}{z}\right)\cdot\frac{n}{2}\right\rfloor\,,\\[1ex]y_S&=\left\lfloor\left(1+\frac{y}{z}\right)\cdot\frac{n}{2}\right\rfloor\,,\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cbegin%7Baligned%7Dx_S%26%3D%5Cleft%5Clfloor%5Cleft%281-%5Cfrac%7Bx%7D%7Bz%7D%5Cright%29%5Ccdot%5Cfrac%7Bn%7D%7B2%7D%5Cright%5Crfloor%5C%2C%2C%5C%5C%5B1ex%5Dy_S%26%3D%5Cleft%5Clfloor%5Cleft%281%2B%5Cfrac%7By%7D%7Bz%7D%5Cright%29%5Ccdot%5Cfrac%7Bn%7D%7B2%7D%5Cright%5Crfloor%5C%2C%2C%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
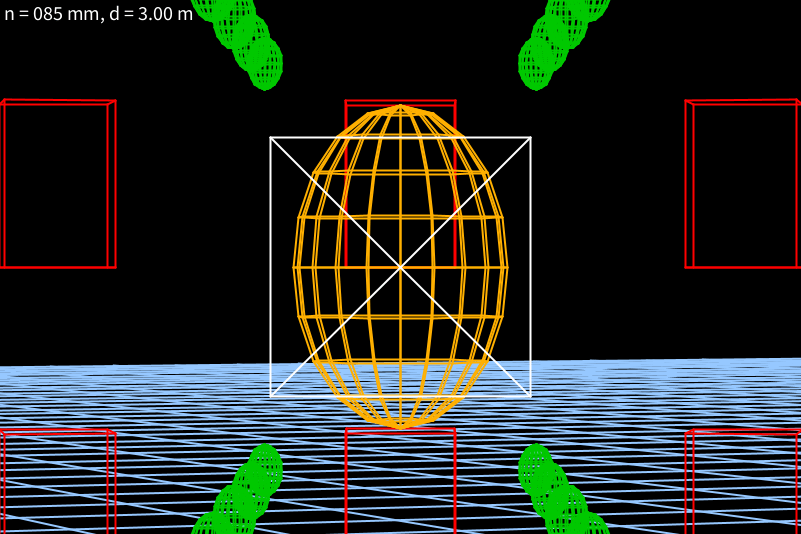
wobei das n hier die Anzahl der Pixel in x– und y-Richtung war. Für einen rechteckigen Sensor haben wir aber z.B. 

![\displaystyle\begin{aligned}x_S&=\left\lfloor\left(1-\frac{x}{z}\right)\cdot\frac{n_x}{2}\right\rfloor\,,\\[1ex]y_S&=\left\lfloor\left(1+\frac{y}{z}\right)\cdot\frac{n_y}{2}\right\rfloor\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cbegin%7Baligned%7Dx_S%26%3D%5Cleft%5Clfloor%5Cleft%281-%5Cfrac%7Bx%7D%7Bz%7D%5Cright%29%5Ccdot%5Cfrac%7Bn_x%7D%7B2%7D%5Cright%5Crfloor%5C%2C%2C%5C%5C%5B1ex%5Dy_S%26%3D%5Cleft%5Clfloor%5Cleft%281%2B%5Cfrac%7By%7D%7Bz%7D%5Cright%29%5Ccdot%5Cfrac%7Bn_y%7D%7B2%7D%5Cright%5Crfloor%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
ergibt.
Für ein unverzerrtes Bild muss das Seitenverhältnis (aspect ratio) der Pixelanzahlen gleich dem Seitenverhältnis der Sensorgröße sein:
Wenn wir das nicht beachten, erhalten wir ein verzerrtes Bild. Der Code in der Methode paintScene() des Rasterizers ist entsprechend:
// lade die Endpunkte der aktuellen Linie
final Point3D v0 = vertices.get(l.v0);
final Point3D v1 = vertices.get(l.v1);
// und berechne ihre screen coordinates
final int x0 = (int)((1.0 - v0.x/v0.z)*width/2.0);
final int y0 = (int)((1.0 + v0.y/v0.z)*height/2.0);
final int x1 = (int)((1.0 - v1.x/v1.z)*width/2.0);
final int y1 = (int)((1.0 + v1.y/v1.z)*height/2.0);
(So ist er schon seit dem ersten Teil, aber bisher waren die Pixelanzahlen width 
height 
In Summe ergibt sich dann aus Sicht der Standardkamera die Animation in Abb. 1.
Code
Die Camera-Klasse speichert jetzt neben der Viewmatrix auch noch die Projektionsmatrix, die über die Methode frustum() geändert werden kann.
// Setzt die Bildschirmbreite auf +/-w/2,
// die Bildschirmhöhe auf +/-h/2 und
// die z-Koordinate des Bildschirms auf -n
void frustum(final float w, final float h, final float n) {
projectionTransform.set(2.0/w, 0.0, 0.0, 0.0,
0.0, 2.0/h, 0.0, 0.0,
0.0, 0.0, 1.0/n, 0.0,
0.0, 0.0, 0.0, 1.0);
}
Breite und Höhe werden dabei nicht in Pixeln gemessen, sondern in den Längeneinheiten, in denen wir unsere Welt basteln. In allen Programmen dieses Beitrags sind das Meter.
Weil View- und Projektionsmatrix getrennt voneinander gespeichert werden, können wir sie auch unabhängig voneinander ändern. In der draw()-Methode positioniert z.B.
// Kamera ausrichten und positionieren
theCamera.setEyeAndLookAt(new Point3D(0.0, 1.0, 3.0),
new Point3D(0.0, 1.0, 0.0),
new Vec3D(0.0, 1.0, 0.0));
// Full frame sensor: 36 mm x 24 mm
theCamera.frustum(0.036, 0.024, 0.135);
die Kamera in der Welt, wobei die y-Richtung nach oben zeigen soll. Anschließend wird die Bildschirm- bzw. Sensorgröße und die Position auf der z-Achse eingestellt. Weil unsere Weltlängeneinheit Meter sein soll, muss für 36 mm Breite und 24 mm Höhe 0.036 bzw. 0.024 eingegeben werden. 0.135 für die z-Koordinate des Schirms bedeutet entsprechend ein 135 mm-Objektiv.
Ohne Aufruf der frustum()-Methode ist die Projektionsmatrix die Einheitsmatrix, was der Größe der Standardkamera entspricht.
Erst vor dem Einfügen der Punkte in den Rasterizer (in der Methode stageLines()) werden die 
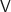
// die Projektions- und View-Transformation der Kamera und die Model-Transformation des
// aktuellen Objekts werden zur Model-View-Projection-Matrix multipliziert
Transform3D PVM = Transform3D_mulABC(camera.projectionTransform, camera.viewTransform, wf.modelTransform);
// jetzt wird die Model-View-Projection-Transformation auf alle Punkte
// angewandt und das Ergebnis eingefügt
for (Point3D v : wf.vertices) {
Point3D p = PVM.apply(v);
vertices.add(p);
// falls die z-Koordinate größer als die bisher maximale
// ist, speichern wir sie
maxZ = max(maxZ, p.z);
}
Sonst hat sich am Rasterizer nichts geändert.
Der Code für Abb. 1, Abb. 2 und Abb. 5 kann hier, hier bzw. hier heruntergeladen werden.
Sichtfeld
Statt Breite w und Höhe h des Schirms direkt anzugeben, kann man auch das Sichtfeld (field of view, fov) angeben, typischerweise in vertikaler Richtung (s. Abb. 7).

Das Sichtfeld ist der Winkelbereich fov, den die Kamera auf den Sensor abbilden kann. Aus Abb. 7 folgt
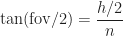
Neben dem Winkel fov brauchen wir zusätzlich entweder die Höhe h oder die Bildweite n. Nehmen wir an, wir kennen n, dann folgt

Sobald die Höhe h bekannt ist, ergibt sich die Breite w mit dem Seitenverhältnis zu

Das könnten wir mit dem Code
float h = 2.0*n*tan(fov/2.0);
theCamera.frustum(h*float(width)/float(height), h, n);
umsetzen. (Im Prinzip könnten wir auch das horizontale Sichtfeld angeben und uns dann mit dem Seitenverhältnis die Höhe ausrechnen.)
Dolly-Zoom
Eine interessante Variation ergibt sich, wenn wir während des Zoomens die Kamera vor- oder zurückbewegen. Dazu wird in der Realität die Kamera mit einem Wagen (Dolly) auf Schienen gestellt.
Abb. 8 zeigt wieder, was wir erreichen möchten. Wenn wir in Abb. 1 heraus gezoomt haben, wurde das Bild der orangenen Kugel kleiner. Fahren wir aber mit der Kamera näher, wird ihr Bild wieder größer. Machen wir das im richtigen Verhältnis, bleibt die (vertikale) Größe der Kugel auf dem Kamerasensor immer gleich. Bei Objekten mit einem anderen Abstand zur Kamera ändert sich allerdings deren Größe am Schirm.
Fahren wir näher heran während wir die Brennweite verringern, scheint sich der Abstand zwischen den grünen Kugeln zu vergrößern. Diesen Effekt hat Alfred Hitchcock im Film Vertigo verwendet, um die Höhenangst des Protagonisten beim Aufstieg in einem Turm zu visualisieren. Vertigo und andere Beispiele werden in diesem Video besprochen.
Dass sich außer der Kamera in dieser Szene nichts bewegt, sieht man wieder aus Sicht einer zweiten Kamera (Abb. 9). Die weiße Pyramide ist jene Kamera, die Abb. 8 filmt und mit
Wenn wir der Kugel am nächsten sind, ist 

Abb. 10 zeigt ein blaues Objekt der Höhe l, das mit ein und derselben Kamera aus verschiedenen Distanzen gefilmt wird. Verringern wir den Abstand d, müssen wir auch die Brennweite n reduzieren, damit die Bildgröße 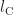

Sowohl in Teil (a) als auch Teil (b) folgt aus dem Strahlensatz:
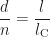
Die Längen l und 

Mit dem Einheitsvektor 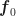


Weil wir den Abstand zur Kugel so verändern, dass ihr Bild am Sensor immer gleich groß bleibt, wird der Rest unserer Welt jetzt so transformiert, wie in Abb. 11 gezeigt.
Im Gegensatz zu Abb. 5 bleibt die verzerrte Kugel jetzt immer gleich weit vor unserer Standardkamera, während der Rest des Universums um ihren Mittelpunkt in z-Richtung skaliert wird.
In dem gezeigten Beispiel war der Kugelmittelpunkt M genau 1 m über dem Ursprung 0. Außerdem war die Kamera gegen die z-Achse gerichtet, weshalb nur die 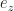
In einem Experiment habe ich statt der Kugel den roten Würfel dahinter in der Kamera gleich groß gelassen. Dabei bewegt sich die Kamera unphysikalisch durch die Kugel hindurch. Nachdem der lookAt-Punkt l aber immer noch der Kugelmittelpunkt war, hat sich die Kamera dabei effektiv umgedreht. Für einen Dolly-Zoom sollte man l also immer in das interessante Objekt zeigen lassen.
Diskussion
Mit der view matrix und jetzt der projection matrix haben wir die volle Kontrolle über die Größe, die Brennweite und die Positionierung der Kamera. Der Vorteil ist, dass wir unsere Objekte wie gewohnt in der Welt positionieren und transformieren können. Um die ganzen Verzerrungen relativ zur Standardkamera kümmert sich die view-projection matrix. Dieser Vorteil hat aber auch den Nachteil, dass das alles in den Matrizenprodukten versteckt ist.
Wie schon erwähnt haben wir nur die einfachst mögliche Projektionsmatrix besprochen. Speziell eine eventuelle far plane müssten wir noch berücksichtigen. Außerdem kann man mit der Projektionsmatrix einfach zwischen einer Zentralprojektion und einer Parallelprojektion (haben wir noch nicht gemacht) umschalten, wenn auch die w-Koordinate der Punkte einbezogen wird.
