Angenommen, man hat eine Messgröße, die man durch eine Zufallsvariable modellieren kann. Der Erwartungswert von sei und die Standardabweichung sei .
Misst man diese Messgröße mehrfach, wird man voraussichtlich verschiedene Werte erhalten, deren Streuung durch die Verteilung von modelliert wird.
Berechnet man den Mittelwert dieser Messungen, kann man ihn durch die Zufallsvariable modellieren. Wenn die Messungen alle voneinander unabhängig waren, gilt für den Erwartungswert des Mittelwertes
und für die Standardabweichung (»Standardfehler«) des Mittelwertes
Diese Formeln gelten unabhängig von der konkreten Verteilung von ; die zweite wird oft auch als »Wurzel-n-Gesetz« bezeichnet.
Wenn man mehrfach den Mittelwert aus Messungen bildet, streuen diese Werte um den Faktor weniger um als die Einzelmessungen.
Als konkretes Beispiel betrachten wir die Füllmenge von Flaschen, die normalverteilt sein soll: . Für diesen Fall gilt exakt, dass auch der Mittelwert normalverteilt ist: .
Misst man die Füllmenge einzelner Flaschen, werden knapp 4 von 10 einen Wert im Intervall haben (links). Nimmt man den Mittelwert der Füllmengen von jeweils 10 Flaschen, werden knapp 9 von 10 dieser Mittelwerte im Intervall liegen.Wenn man nicht weiß, dass ist, kann man die Füllmenge einer Flasche messen. Mit 38.3% Wahrscheinlichkeit wird dieser Wert nicht mehr als von abweichen. Nimmt man den Mittelwert der Füllmengen von 10 Flaschen, erhöht sich diese Wahrscheinlichkeit auf 88.6%.
Durch die Mittelwertbildung kommt man also wahrscheinlich »viel näher« an (das unbekannte) heran, als durch eine Einzelmessung.



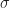


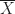
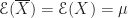




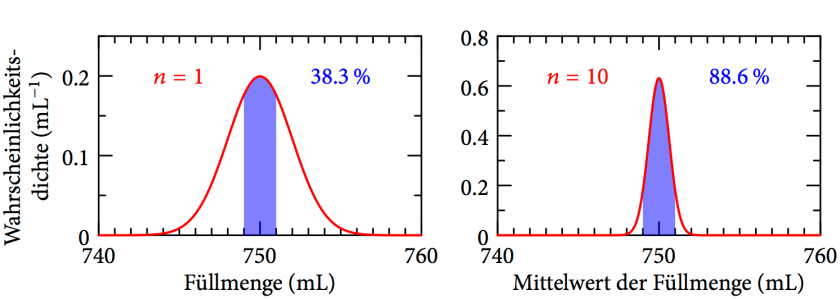
![[749\,\text{mL};751\,\text{mL}]](https://s0.wp.com/latex.php?latex=%5B749%5C%2C%5Ctext%7BmL%7D%3B751%5C%2C%5Ctext%7BmL%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)


