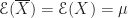In Teil 3 haben wir aus unseren »Schattenmessungen« ein sehr grobes Bild unserer Objekte rekonstruiert. Im Folgenden sehen wir uns einige bessere Rekonstruktionen an.


In Teil 3 haben wir aus unseren »Schattenmessungen« ein sehr grobes Bild unserer Objekte rekonstruiert. Im Folgenden sehen wir uns einige bessere Rekonstruktionen an.
In Teil 1 ging es um die grundsätzliche Funktionsweise eines CT. In Teil 2 haben wir verschiedene Radon-Transformationen unserer Objekte gesehen.
Jetzt geht es darum, wie wir die Lage und Form unserer Objekte aus der Radon-Transformation rekonstruieren können. Es gibt mehrere Methoden, aber eine der einfachsten – und auch (mit Verbesserungen) in medizinischen CTs verwendete – ist die Rückprojektion (backprojection).
In Teil 1 haben wir gesehen, das bei einem CT »Schattenbilder« aus verschiedenen Richtungen gemessen werden. Alle Schattenbilder aus verschiedenen Richtungen zusammen nennt man die Radon-Transformation unserer Objekte.
Dieser Eintrag startet eine Serie von Beiträgen zur Computertomographie. Ziel ist es, im Rahmen einer HTL-Diplomarbeit ein (2-dimensionales) CT mit sichtbarem Licht zu bauen.
Das Grundprinzip ist in Abb. 1 gezeigt. In einer Ebene befinden sich verschiedene Objekte (blau), die mehr oder weniger Licht durchlassen. Aus einer bestimmten Richtung fallen parallele Lichtstrahlen (rot) ein, wodurch die Objekte einen Schatten auf einen Lichtdetektor werfen. Im medizinischen Bereich handelt es sich bei dem Licht um Röntgenstrahlen, aber das Grundprinzip ist für sichtbares Licht identisch.
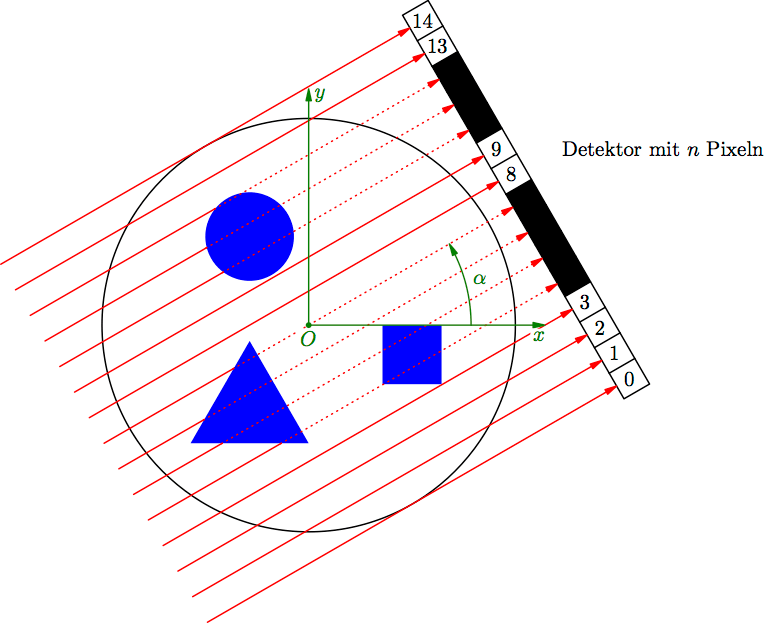
Angenommen, man hat eine Messgröße, die man durch eine Zufallsvariable 

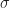
Misst man diese Messgröße mehrfach, wird man voraussichtlich verschiedene Werte erhalten, deren Streuung durch die Verteilung von
Berechnet man den Mittelwert 

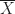
und für die Standardabweichung (»Standardfehler«) des Mittelwertes
Diese Formeln gelten unabhängig von der konkreten Verteilung von
Im letzten Beitrag haben wir gesehen, wie in einem längeren Münzwurfexperiment die relative Häufigkeit für Kopf immer näher an 1/2 herangekommen ist. Obwohl es keine Garantie dafür gibt, dass es so sein muss, ist so eine Stabilisierung von relativen Häufigkeiten und anderen Messgrößen oft zu beobachten. Diese Erfahrungstatsache nennt man das empirische »Gesetz« der großen Zahlen.
Wie kann man sich das erklären?
Wahrscheinlichkeiten sind Erwartungen – um nicht zu sagen Hoffnungen – darüber, wie oft ein bestimmtes Ereignis bei oftmaliger Wiederholung eines Zufallsexperiments (unter gleichen Bedingungen) eintreten wird. Genauer gesagt, geht es um die relative Häufigkeit eines Ereignisses.
Diese Erwartungen hängen von unserem Informationsstand ab. Wie man zu sinnvollen Erwartungen kommt, ist ein Kapitel für sich. Erwartungen können falsch sein; selbst »richtige« Erwartungen können enttäuscht werden.
Darüber hinaus ist unklar, was mit oftmaliger Wiederholung genau gemeint ist. 100-mal, 1000-mal, 1 Milliarde Mal?
Für viele Münzwurfexperimente ist es sinnvoll, eine Wahrscheinlichkeit für Kopf von 1/2 anzunehmen. Die rote Linie in der folgenden Abbildung zeigt, wie sich die relative Häufigkeit für Kopf im Lauf einer längeren Münzwurfserie geändert hat.
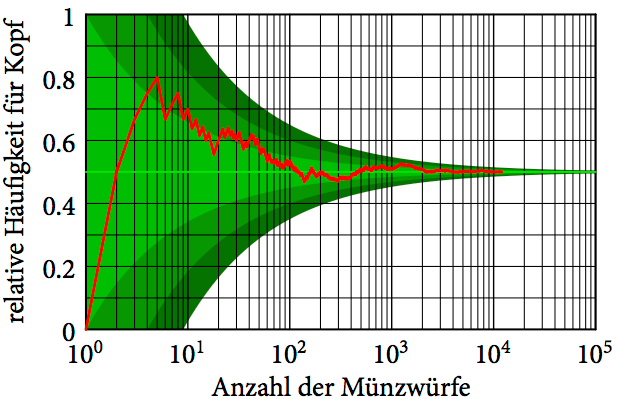
 -,
-,  – bzw.
– bzw. 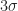 -Umgebungen unserer Erwartung dar. Die horizontale Achse ist logarithmisch skaliert, um den Beginn deutlicher zeigen zu können.
-Umgebungen unserer Erwartung dar. Die horizontale Achse ist logarithmisch skaliert, um den Beginn deutlicher zeigen zu können.